In numerical linear algebra, the conjugate gradient method is an iterative method for numerically solving the linear system
where is symmetric positive-definite, without computing explicitly. The conjugate gradient method can be derived from several different perspectives, including specialization of the conjugate direction method[1] for optimization, and variation of the Arnoldi/Lanczos iteration for eigenvalue problems.
The intent of this article is to document the important steps in these derivations.
Conjugate direction
The conjugate gradient method can be seen as a special case of the conjugate direction method applied to minimization of the quadratic function
which allows us to apply geometric intuition.
Line search
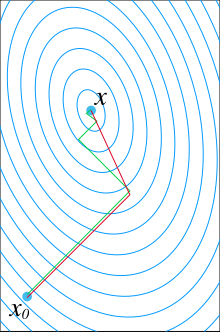
Geometrically, the quadratic function can be equivalently presented by writing down its value at every point in space. The points of equal value make up its contour surfaces, which are concentric ellipsoids with the equation for varying . As decreases, the ellipsoids become smaller and smaller, until at its minimal value, the ellipsoid shrinks to their shared center.
Minimizing the quadratic function is then a problem of moving around the plane, searching for that shared center of all those ellipsoids. The center can be found by computing explicitly, but this is precisely what we are trying to avoid.
The simplest method is greedy line search, where we start at some point , pick a direction somehow, then minimize . This has a simple closed-form solution that does not involve matrix inversion:Geometrically, we start at some point on some ellipsoid, then choose a direction and travel along that direction, until we hit the point where the ellipsoid is minimized in that direction. This is not necessarily the minimum, but it is progress towards it. Visually, it is moving along a line, and stopping as soon as we reach a point tangent to the contour ellipsoid.
We can now repeat this procedure, starting at our new point , pick a new direction , compute , etc.
We can summarize this as the following algorithm:
Start by picking an initial guess , and compute the initial residual , then iterate:
where are to be picked. Notice in particular how the residual is calculated iteratively step-by-step, instead of anew every time:It is possibly true that prematurely, which would bring numerical problems. However, for particular choices of , this will not occur before convergence, as we will prove below.
Conjugate directions
If the directions are not picked well, then progress will be slow. In particular, the gradient descent method would be slow. This can be seen in the diagram, where the green line is the result of always picking the local gradient direction. It zig-zags towards the minimum, but repeatedly overshoots. In contrast, if we pick the directions to be a set of mutually conjugate directions, then there will be no overshoot, and we would obtain the global minimum after steps, where is the number of dimensions.
Two conjugate diameters of an ellipse. Each edge of the bounding parallelogram is parallel to one of the diameters.
The concept of conjugate directions came from classical geometry of ellipse. For an ellipse, two semi-axes center are mutually conjugate with respect to the ellipse iff the lines are parallel to the tangent bounding parallelogram, as pictured. The concept generalizes to n-dimensional ellipsoids, where n semi-axes are mutually conjugate with respect to the ellipsoid iff each axis is parallel to the tangent bounding parallelepiped. In other words, for any , the tangent plane to the ellipsoid at is a hyperplane spanned by the vectors , where is the center of the ellipsoid.
Note that we need to scale each directional vector by a scalar , so that falls exactly on the ellipsoid.
Given an ellipsoid with equation for some constant , we can translate it so that its center is at origin. This changes the equation to for some other constant . The condition of tangency is then:that is, for any .
The conjugate direction method is imprecise in the sense that no formulae are given for selection of the directions . Specific choices lead to various methods including the conjugate gradient method and Gaussian elimination.
Gram–Schmidt process
We can tabulate the equations that we need to set to zero:
0
1
2
3
0
1
2
This resembles the problem of orthogonalization, which requires for any , and for any . Thus the problem of finding conjugate axes is less constrained than the problem of orthogonalization, so the Gram–Schmidt process works, with additional degrees of freedom that we can later use to pick the ones that would simplify the computation:
Arbitrarily set .
Arbitrarily set , then modify it to .
Arbitrarily set , then modify it to .
...
Arbitrarily set , then modify it to .
The most natural choice of is the gradient. That is, . Since conjugate directions can be scaled by a nonzero value, we scale it by for notational cleanness, obtaining Thus, we have . Plugging it in, we have the conjugate gradient algorithm:Proposition. If at some point, , then the algorithm has converged, that is, .
Proof. By construction, it would mean that , that is, taking a conjugate gradient step gets us exactly back to where we were. This is only possible if the local gradient is already zero.
Simplification
This algorithm can be significantly simplified by some lemmas, resulting in the conjugate gradient algorithm.
Lemma 1. and .
Proof. By the geometric construction, the tangent plane to the ellipsoid at contains each of the previous conjugate direction vectors . Further, is perpendicular to the tangent, thus . The second equation is true since by construction, is a linear transform of .
Lemma 2..
Proof. By construction, , now apply lemma 1.
Lemma 3..
Proof. By construction, we have , thusNow apply lemma 1.
Plugging lemmas 1-3 in, we have and , which is the proper conjugate gradient algorithm.
Arnoldi/Lanczos iteration
The conjugate gradient method can also be seen as a variant of the Arnoldi/Lanczos iteration applied to solving linear systems.
The general Arnoldi method
In the Arnoldi iteration, one starts with a vector and gradually builds an orthonormal basis of the Krylov subspace
Put in matrix form, the iteration is captured by the equation
where
with
When applying the Arnoldi iteration to solving linear systems, one starts with , the residual corresponding to an initial guess . After each step of iteration, one computes and the new iterate .
The direct Lanczos method
For the rest of discussion, we assume that is symmetric positive-definite. With symmetry of , the upper Hessenberg matrix becomes symmetric and thus tridiagonal. It then can be more clearly denoted by
This enables a short three-term recurrence for in the iteration, and the Arnoldi iteration is reduced to the Lanczos iteration.
In fact, there are short recurrences for and as well:
With this formulation, we arrive at a simple recurrence for :
The relations above straightforwardly lead to the direct Lanczos method, which turns out to be slightly more complex.
The conjugate gradient method from imposing orthogonality and conjugacy
If we allow to scale and compensate for the scaling in the constant factor, we potentially can have simpler recurrences of the form:
As premises for the simplification, we now derive the orthogonality of and conjugacy of , i.e., for ,
The residuals are mutually orthogonal because is essentially a multiple of since for , , for ,
To see the conjugacy of , it suffices to show that is diagonal:
is symmetric and lower triangular simultaneously and thus must be diagonal.
Now we can derive the constant factors and with respect to the scaled by solely imposing the orthogonality of and conjugacy of .
Due to the orthogonality of , it is necessary that . As a result,
Similarly, due to the conjugacy of , it is necessary that . As a result,
This completes the derivation.
References
^Conjugate Direction Methods http://user.it.uu.se/~matsh/opt/f8/node5.html
Hestenes, M. R.; Stiefel, E. (December 1952). "Methods of conjugate gradients for solving linear systems" (PDF). Journal of Research of the National Bureau of Standards. 49 (6): 409. doi:10.6028/jres.049.044.
Shewchuk, Jonathan Richard. "An introduction to the conjugate gradient method without the agonizing pain." (1994)
Saad, Y. (2003). "Chapter 6: Krylov Subspace Methods, Part I". Iterative methods for sparse linear systems (2nd ed.). SIAM. ISBN 978-0-89871-534-7.