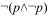Théorisation post hoc


Cet article ne cite pas suffisamment ses sources ().
Si vous disposez d'ouvrages ou d'articles de référence ou si vous connaissez des sites web de qualité traitant du thème abordé ici, merci de compléter l'article en donnant les références utiles à sa vérifiabilité et en les liant à la section « Notes et références ».
En pratique : Quelles sources sont attendues ? Comment ajouter mes sources ?
En statistiques, une hypothèse post hoc est une hypothèse émise après une analyse initiale des données qui suggéraient ladite hypothèse. Cette hypothèse est susceptible d'être acceptée même si elle est fausse, en raison de la possible implication d'un raisonnement circulaire (double diping (en)). Ainsi, quelque chose semble vrai dans un ensemble limité de données et, par généralisation à outrance, il est supposé que c'est vrai en général. Générer des hypothèses basées sur des données déjà observées, sans les avoir testées sur de nouvelles données, est appelé théorisation post hoc (du latin post hoc, « après coup »).
La procédure appropriée consiste à tester toute hypothèse sur un ensemble de données qui n'a pas été utilisé pour générer l'hypothèse.
Généralités
Tester une hypothèse suggérée par les données peut très facilement entraîner des faux positifs (erreurs de type I (en) ). Si l’on regarde assez longtemps et dans suffisamment d’endroits différents, on finit par trouver des données pour étayer n’importe quelle hypothèse. Cependant, ces données positives ne constituent pas en elles-mêmes une preuve que l’hypothèse est correcte. Les résultats négatifs des tests rejetés sont tout aussi importants, car ils donnent une idée de la fréquence des résultats positifs par rapport au hasard. Mener une expérience, observer un modèle dans les données, proposer une hypothèse à partir de ce modèle, puis utiliser les mêmes données expérimentales comme preuve de la nouvelle hypothèse est extrêmement suspect, car les données de toutes les autres expériences, achevées ou potentielles, ont essentiellement été "jetées" en choisissant de n'examiner que les expériences qui ont suggéré la nouvelle hypothèse en premier lieu.
Un large ensemble de tests tels que décrits ci-dessus gonfle considérablement la probabilité d'erreurs de type I, car toutes les données, à l'exception des données les plus favorables à l'hypothèse, sont écartées. Il s'agit d'un risque, non seulement dans le test d'hypothèses, mais dans toute inférence statistique, car il est souvent problématique de décrire avec précision le processus qui a été suivi pour rechercher et éliminer les données. En d’autres termes, on souhaite conserver toutes les données (qu’elles tendent à soutenir ou à réfuter l’hypothèse) issues des « bons tests », mais il est parfois difficile de comprendre ce qu’est un « bon test ». Il s'agit d'un problème particulier en modélisation statistique, où de nombreux modèles différents sont rejetés par essais et erreurs avant de publier un résultat.
L'erreur est particulièrement répandue dans l'exploration de données et l'apprentissage automatique. Cela se produit également couramment dans l'édition universitaire (en), où seuls les rapports faisant état de résultats positifs plutôt que négatifs ont tendance à être acceptés, ce qui entraîne un effet connu sous le nom de biais de publication.
Articles connexes : Sur-ajustement et biais de publication.
Procédures correctes
Toutes les stratégies permettant de tester solidement les hypothèses suggérées par les données impliquent d’inclure un plus large éventail de tests pour tenter de valider ou de réfuter la nouvelle hypothèse. Ceux-ci inclus :
- La collecte d'échantillons de confirmation
- La validation croisée
- Des méthodes de compensation pour les comparaisons multiples (en)
- Des études de simulation comprenant une représentation adéquate des tests multiples réellement impliqués
Le test développé par Henry Scheffé (en) serait un bon moyen pour éviter les erreurs liées aux hypothèses post hoc[1].
Voir aussi
- Correction de Bonferroni
- Data dredging
- HARKing
- Analyse prédictive
- Sophisme du tireur d'élite texan
Notes et références
- (en) Cet article est partiellement ou en totalité issu de l’article de Wikipédia en anglais intitulé « Testing hypotheses suggested by the data » (voir la liste des auteurs).
- ↑ Henry Scheffé, "A Method for Judging All Contrasts in the Analysis of Variance", Biometrika, 40, pages 87–104 (1953). DOI 10.1093/biomet/40.1-2.87
 Portail de la logique
Portail de la logique  Portail des probabilités et de la statistique
Portail des probabilités et de la statistique