標準正規分布 の箱ひげ図 および確率密度関数 N (0, σ 2 )確率密度関数 ( かくりつみつどかんすう 、( 英 : probability density function 、PDF)とは、確率論 において、連続型確率変数 がある値をとるという事象の確率密度を記述する関数である。確率変数がある範囲の値をとる確率を、その範囲にわたって確率密度関数を積分 することにより得ることができるよう定義される。確率密度関数の値域 は非負の実数 であり、定義域 全体を積分すると1である。
例えば単変数の確率密度関数を平面上のグラフに表現して、x 軸に確率変数の値を、y 軸に確率密度を採った場合、求めたい範囲(x 値)の下限値と上限値での垂直線と、変数グラフ曲線と y = 0
「確率分布関数」 (probability distribution function)[1] [2]
他の資料に拠れば「確率密度関数」は値の集合に対する関数として定義されたり、累積分布関数 との関係で言及されたり、確率質量関数 の意味で使われたりする。さらには、密度関数 (density function) という用語が確率質量関数 の意味で用いられている場合もある[3]
例 例として、寿命が4〜6時間程度のバクテリアがいると仮定する。この時、特定のバクテリアが丁度 5時間で死亡する確率はどれ位だろうか? 答えは0% である。およそ 5時間で寿命を迎えるバクテリアはたくさん居るが、正確に 5.0000000000…時間で死ぬことはない。
一方で、5〜5.01時間で死亡する確率はどうだろうか? 例えば、これが2%だとする。では、その1 / 10 1 / 10 1 / 10
上記の3例において、『「特定の時間範囲内に死亡する確率」を「その範囲の長さ」で割った値』に着目すると、1時間につき 2 に定まることが分かる。例えば、5〜5.01時間の0.01時間の範囲でバクテリアが死亡する確率は0.02であり、確率 0.02 ÷ 0.01時間 = 2時間−1 である。この2時間−1 (毎時200%)という量を、5時間時点での確率密度 と呼ぶ。
従って、「バクテリアの寿命が5時間である確率」を問われた時、真の答えは0%であるが、より実用的には、2時間−1 dt であると言える。これは、無限小 の時間範囲 dt 内で、バクテリアが死亡する確率である。例えば、丁度5時間〜5時間 + 1ナノ秒の寿命である確率は、2時間−1 × 1ナノ秒 ≈ 6 × 10−13 である。
これを確率密度関数 f を用いて、f (5時間)= 2時間−1 と表現することができる。f を任意の時間範囲(微小に限らない)で積分することで、当該時間範囲内でバクテリアの寿命が尽きる確率を求めることができる。
絶対連続確率分布での定義 絶対連続確率分布では確率密度関数が存在する。確率変数 X の確率密度関数 fX を考え、fX が非負のルベーグ可積分 な関数であるとする。ここで、
P ( a ≤ X ≤ b ) = ∫ a b f X ( x ) d x {\displaystyle \operatorname {P} (a\leq X\leq b)=\int _{a}^{b}f_{X}(x)\,dx} である。従って、もし FX を X の累積分布関数 とすると、
F X ( x ) = ∫ − ∞ x f X ( u ) d u {\displaystyle F_{X}(x)=\int _{-\infty }^{x}f_{X}(u)\,du} となり、
f X ( x ) = d d x F X ( x ) {\displaystyle f_{X}(x)={\frac {d}{dx}}F_{X}(x)} となる。直観的に、微小区間 [x , x + dx ] に含まれる値を X がとる確率は fX (x )dx
正式な定義 (この定義は確率の公理 によりあらゆる確率分布に拡張できる。) 完全加法族 ( X , A ) {\displaystyle ({\mathcal {X}},{\mathcal {A}})} R n ボレル集合 を考えたもの)中に存在する確率変数 X は、 ( X , A ) {\displaystyle ({\mathcal {X}},{\mathcal {A}})} X ∗ P 確率分布 する。 ( X , A ) {\displaystyle ({\mathcal {X}},{\mathcal {A}})} μ に関する X の密度 は、ラドン=ニコディムの定理 より
f = d X ∗ P d μ {\displaystyle f={\frac {dX_{*}P}{d\mu }}} である。これは、f は次の性質を持つ任意の可測関数であることを意味する。あらゆる可測集合 A ∈ A {\displaystyle A\in {\mathcal {A}}}
P ( X ∈ A ) = ∫ X − 1 A d P = ∫ A f d μ {\displaystyle \operatorname {P} (X\in A)=\int _{X^{-1}A}\,dP=\int _{A}f\,d\mu } 注意点 上記の連続単変数の場合は、標準測度はルベーグ測度 である。離散確率変数 における確率質量関数 は標本空間(通常、整数 全体の集合またはその部分集合)内での数え上げ測度 に対応する。
任意の測度で密度が定義できる訳ではないことに注意。例えば、連続確率分布に数え上げ測度を対応させることはできない。さらに、対応する測度が存在した時、密度はほとんど至るところで一意的である。
詳細 確率質量関数とは異なり、確率密度関数は1より大きな値を取りうる。例えば、区間 [0, 1 / 2 の連続一様分布 の確率密度関数は範囲 0 ≤ x ≤ 1 / 2 f (x ) = 2f (x ) = 0
正規分布 は下記の確率密度関数を持つ。
f ( x ) = 1 2 π e − x 2 / 2 {\displaystyle f(x)={\frac {1}{\sqrt {2\pi }}}\;e^{-x^{2}/2}} 確率変数 X とその確率密度関数 f が与えられた時、X の期待値 は(値が存在する場合は)次の式で求められる。
E [ X ] = ∫ − ∞ ∞ x f ( x ) d x {\displaystyle \operatorname {E} [X]=\int _{-\infty }^{\infty }x\,f(x)\,dx} 全ての確率分布が確率密度関数を持つとは限らない。離散型確率変数 が持たない他にも、カントール分布 は連続確率分布 であるにもかかわらず、範囲内のあらゆる点で正の確率を持たないため、確率密度関数を持たない。
確率分布はその累積分布関数 F (x )絶対連続 である場合にのみ確率密度関数 f を持つ。この場合 F はほとんど至るところで微分可能で、f は F のラドン=ニコディムの定理 である:
d d x F ( x ) = f ( x ) {\displaystyle {\frac {d}{dx}}F(x)=f(x)} 累積分布関数が連続の場合、確率変数 がある値 a をとる確率 P(X = a ) は常に0である。
2つの確率密度関数 f , g 確率分布 から採られたと言える。
統計力学 の分野では、累積分布関数のラドン=ニコディム微分と確率密度関数との関係を非形式的に書いた以下の式が確率密度関数の定義として用いられる。
dt が無限小の時、X が区間(t , t + dt )f (t )dt
P ( t < X < t + d t ) = f ( t ) d t . {\displaystyle \operatorname {P} (t<X<t+dt)=f(t)\,dt.} 離散分布と連続分布との結合 ディラックのデルタ関数 を用いると、ある種の離散型確率変数によって連続型確率変数および離散型確率変数の確率密度関数を統一的に表現することができる。試しに、2つの値しか採らない離散型確率変数 を考える。例えばラーデマッヘル分布(英語版) ―すなわちそれぞれ 1 / 2 −1 または 1 の値を採る分布―である。この変数の確率の密度は
f ( t ) = 1 2 ( δ ( t + 1 ) + δ ( t − 1 ) ) {\displaystyle f(t)={\frac {1}{2}}(\delta (t+1)+\delta (t-1))} である。より一般化すると、離散変数が n 通りの実数値を取り得る時、その離散値を x 1 , …, xn p 1 , …, pn
f ( t ) = ∑ i = 1 n p i δ ( t − x i ) {\displaystyle f(t)=\sum _{i=1}^{n}p_{i}\,\delta (t-x_{i})} と表記される。
これは実質的に、離散型確率変数と連続型確率変数を統合している。例として、上記の表現からは連続変数と同様に離散変数について統計学的パラメータ(平均 、分散、尖度 など)を計算可能である。
パラメータ化 確率密度関数または確率質量関数 を任意の媒介変数 でパラメータ化することがしばしばある。例えば、正規分布 の密度は平均 μ および分散 σ 2
f ( x ; μ , σ 2 ) = 1 σ 2 π exp [ − 1 2 ( x − μ σ ) 2 ] . {\displaystyle f(x;\mu ,\sigma ^{2})={\frac {1}{\sigma {\sqrt {2\pi }}}}\exp {\biggl [}-{\frac {1}{2}}\left({\frac {x-\mu }{\sigma }}\right)^{2}{\biggr ]}.} このとき密度の族の定義域 と族のパラメータの定義域との違いに留意することが重要である。パラメータの値が異なると、同じ標本空間 (変数が取り得る全ての値の集合で、同一である)に属する異なる確率変数 の分布を表現することになる。その標本空間は、その分布の族が示している確率変数の族の定義域である。与えられたパラメータの集合は、そのパラメータを用いた共通の関数として確率密度関数を記述できる確率分布族の内の1つを指す。確率分布の観点からすると、パラメータは定数なので、確率密度関数に変数を含まずパラメータのみを含む場合、パラメータは分布の正規化係数(英語版) (定義域全域での確率=1になる様に調整する係数)の一部を成す。この正規化係数は分布のカーネル(英語版) 外にある。
パラメータが定数なので、さらに異なるパラメータで再パラメータ化して族の中に他の確率変数を位置付けることは、単に古いパラメータを捨てて式の中に新しいパラメータを置くだけに過ぎない。しかし、確率密度の定義域を変更することには慎重さが必要で、作業量が多くなる。下記の#従属変数と変数変換 欄を参照。
多変量に関する確率密度関数 同時確率密度関数 n 個の連続型確率変数 X 1 , …, Xn 同時確率密度関数 と呼ばれる確率密度関数を定義することができる。この確率密度関数は n 次元空間の定義域 D 中の n 個の変数 X 1 , …, Xn
P ( X 1 , ⋯ , X N ∈ D ) = ∫ D f X 1 , ⋯ , X N ( x 1 , ⋯ , x N ) d x 1 ⋯ d x N . {\displaystyle \operatorname {P} \left(X_{1},\cdots ,X_{N}\in D\right)=\int _{D}f_{X_{1},\cdots ,X_{N}}(x_{1},\cdots ,x_{N})\,dx_{1}\cdots dx_{N}.} もし F (x 1 , …, xn ) = Pr(X 1 ≤ x 1 , …, Xn ≤ xn ) がベクトル (X 1 , …, Xn ) の同時累積分布関数 ならば、同時確率密度関数を偏微分で導くことができる。
f ( x ) = ∂ n F ∂ x 1 ⋯ ∂ x n | x {\displaystyle f(x)={\frac {\partial ^{n}F}{\partial x_{1}\cdots \partial x_{n}}}{\bigg |}_{x}} 周辺確率密度関数 i = 1, 2, …, n fXi (xi )Xi のみの確率密度関数とする。これは周辺確率密度関数 と呼ばれ、確率変数 X 1 , …, Xn Xi 以外の n − 1
f X i ( x i ) = ∫ f ( x 1 , ⋯ , x n ) d x 1 ⋯ d x i − 1 d x i + 1 ⋯ d x n . {\displaystyle f_{X_{i}}(x_{i})=\int f(x_{1},\cdots ,x_{n})\,dx_{1}\cdots dx_{i-1}\,dx_{i+1}\cdots dx_{n}.} 独立 同時確率密度関数を構成する連続型確率変数 X 1 , …, Xn
f X 1 , ⋯ , X n ( x 1 , ⋯ , x n ) = f X 1 ( x 1 ) ⋯ f X n ( x n ) {\displaystyle f_{X_{1},\cdots ,X_{n}}(x_{1},\cdots ,x_{n})=f_{X_{1}}(x_{1})\cdots f_{X_{n}}(x_{n})} である。それぞれの周辺確率密度関数は下記で表される。
f X i ( x i ) = f i ( x i ) ∫ f i ( x ) d x {\displaystyle f_{X_{i}}(x_{i})={\frac {f_{i}(x_{i})}{\int f_{i}(x)\,dx}}} 例 以下に2変数での基本的な例を記す。2次元の確率ベクトル (X , Y ) を R → {\displaystyle {\vec {R}}} x , y 象限 で得られた R → {\displaystyle {\vec {R}}}
P ( X > 0 , Y > 0 ) = ∫ 0 ∞ ∫ 0 ∞ f X , Y ( x , y ) d x d y {\displaystyle \operatorname {P} \left(X>0,Y>0\right)=\int _{0}^{\infty }\int _{0}^{\infty }f_{X,Y}(x,y)\,dx\,dy} である。
従属変数と変数変換 確率変数 X の確率密度関数が fX (x )Y = g (X )f g (X )fY
関数 g が単調写像 である時、その結果得られる確率密度関数は
f Y ( y ) = | d d y ( g − 1 ( y ) ) | ⋅ f X ( g − 1 ( y ) ) {\displaystyle f_{Y}(y)=\left|{\frac {d}{dy}}(g^{-1}(y))\right|\cdot f_{X}(g^{-1}(y))} である。ここで g −1 逆写像 である。
このことは微分範囲に含まれる確率が変数変換後も不変であることからも分かる。つまり、
| f Y ( y ) d y | = | f X ( x ) d x | , {\displaystyle \left|f_{Y}(y)\,dy\right|=\left|f_{X}(x)\,dx\right|,} または
f Y ( y ) = | d x d y | f X ( x ) = | d d y ( x ) | f X ( x ) = | d d y ( g − 1 ( y ) ) | f X ( g − 1 ( y ) ) = f X ( g − 1 ( y ) ) | g ′ ( g − 1 ( y ) ) | {\displaystyle f_{Y}(y)=\left|{\frac {dx}{dy}}\right|f_{X}(x)=\left|{\frac {d}{dy}}(x)\right|f_{X}(x)=\left|{\frac {d}{dy}}(g^{-1}(y))\right|f_{X}(g^{-1}(y))={\frac {f_{X}(g^{-1}(y))}{|g'(g^{-1}(y))|}}} である。一方、単調写像でない確率密度関数 y は
∑ k = 1 n ( y ) | d d y g k − 1 ( y ) | ⋅ f X ( g k − 1 ( y ) ) {\displaystyle \sum _{k=1}^{n(y)}\left|{\frac {d}{dy}}g_{k}^{-1}(y)\right|\cdot f_{X}(g_{k}^{-1}(y))} (n (y )g (x ) = y x の解の数、g k −1 (y )
これを見ると、期待値 E [g (X )]Y = g (X )f g (X )
E [ g ( X ) ] = ∫ − ∞ ∞ y f g ( X ) ( y ) d y {\displaystyle \operatorname {E} [g(X)]=\int _{-\infty }^{\infty }yf_{g(X)}(y)\,dy} を計算するよりはむしろ、
E [ g ( X ) ] = ∫ − ∞ ∞ g ( x ) f X ( x ) d x {\displaystyle \operatorname {E} [g(X)]=\int _{-\infty }^{\infty }g(x)f_{X}(x)\,dx} を計算する方がよい。
X と g (X )g が単射 である必要はない。前者より後者の計算が簡単である場合がある。
多変量 上記の式は、1つよりも多くの変数に依存する変数(y と書く)に一般化できる。y が依存する変数の確率密度関数を f (x 1 , …, xn )y = g (x 1 , …, xn )[要出典
∫ y = g ( x 1 , ⋯ , x n ) f ( x 1 , ⋯ , x n ) ∑ j = 1 n ∂ g ∂ x j ( x 1 , ⋯ , x n ) 2 d V {\displaystyle \int \limits _{y=g(x_{1},\cdots ,x_{n})}{\frac {f(x_{1},\cdots ,x_{n})}{\sqrt {\sum _{j=1}^{n}{\frac {\partial g}{\partial x_{j}}}(x_{1},\cdots ,x_{n})^{2}}}}\;dV} となる。ただし積分は添え字の方程式の (n − 1) 次元の解全体を渡り、記号 dV は実際の計算にはこの解のパラメータ化に置き換えなければならない。変数 x 1 , …, xn
これからより直感的な表現が導かれる。x f の n 次元確率変数とする。H を全単射 で微分可能な関数として y H (x y g を持つ:
g ( y ) = f ( x ) | det ( d x d y ) | {\displaystyle g(\mathbf {y} )=f(\mathbf {x} )\left\vert \det \left({\frac {\mathrm {d} \mathbf {x} }{\mathrm {d} \mathbf {y} }}\right)\right\vert } ここで微分は H の逆関数のヤコビ行列 の y
独立性を仮定してデルタ関数 を用いると、以下のように同じ結果が得られる。
独立な確率変数 Xi , i = 1, 2, …n fXi (xi )Y = G (X 1 , X 2 , …Xn )Y の確率密度関数 fY (y )fXi (xi )
f Y ( y ) = ∫ − ∞ ∞ ∫ − ∞ ∞ ⋯ ∫ − ∞ ∞ f X 1 ( x 1 ) f X 2 ( x 2 ) ⋯ f X n ( x n ) δ ( y − G ( x 1 , x 2 , ⋯ , x n ) ) d x 1 d x 2 ⋯ d x n {\displaystyle f_{Y}(y)=\int _{-\infty }^{\infty }\int _{-\infty }^{\infty }\cdots \int _{-\infty }^{\infty }f_{X_{1}}(x_{1})f_{X_{2}}(x_{2})\cdots f_{X_{n}}(x_{n})\delta (y-G(x_{1},x_{2},\cdots ,x_{n}))\,dx_{1}\,dx_{2}\,\cdots dx_{n}} 独立な確率変数の和の確率密度関数 2つの独立な確率変数 U と V がそれぞれ確率密度関数を持つ時、和 U + V の確率密度関数は両確率密度関数の畳み込み で表される。
f U + V ( x ) = ∫ − ∞ ∞ f U ( y ) f V ( x − y ) d y = ( f U ∗ f V ) ( x ) {\displaystyle f_{U+V}(x)=\int _{-\infty }^{\infty }f_{U}(y)f_{V}(x-y)\,dy=\left(f_{U}*f_{V}\right)(x)} この関係は、N 個の独立な確率変数 U 1 , …, UN
f U 1 + ⋯ + U N ( x ) = ( f U 1 ∗ ⋯ ∗ f U N ) ( x ) {\displaystyle f_{U_{1}+\cdots +U_{N}}(x)=\left(f_{U_{1}}*\cdots *f_{U_{N}}\right)(x)} これは下記に示す独立な確率変数の商の場合と同様に、2通りの変数変換 Y = U + V Z = V
独立な確率変数の積と商の確率密度関数 2つの独立な確率変数 U と V がそれぞれ確率密度関数を持つ時、積 UV U / V
商の確率密度関数 2つの独立な確率変数 U と V の商 Y = U / V
Y = U V {\displaystyle Y={\frac {U}{V}}} Z = V {\displaystyle Z=V} この時、同時確率密度関数 p (Y , Z )U , V Y , Z Y は同時確率密度関数から Z を周辺化することで導出できる。
その逆変換は、
U = Y Z {\displaystyle U=YZ} V = Z {\displaystyle V=Z} である。
この変換のヤコビ行列 J ( U , V | Y , Z ) {\displaystyle J(U,V|Y,Z)}
| ∂ U ∂ Y ∂ U ∂ Z ∂ V ∂ Y ∂ V ∂ Z | = | Z Y 0 1 | = | Z | {\displaystyle {\begin{vmatrix}{\frac {\partial U}{\partial Y}}&{\frac {\partial U}{\partial Z}}\\{\frac {\partial V}{\partial Y}}&{\frac {\partial V}{\partial Z}}\\\end{vmatrix}}={\begin{vmatrix}Z&Y\\0&1\\\end{vmatrix}}=|Z|} である。
従って、
p ( Y , Z ) = p ( U , V ) J ( U , V | Y , Z ) = p ( U ) p ( V ) J ( U , V | Y , Z ) = p U ( Y Z ) p V ( Z ) | Z | {\displaystyle p(Y,Z)=p(U,V)\,J(U,V|Y,Z)=p(U)\,p(V)\,J(U,V|Y,Z)=p_{U}(YZ)\,p_{V}(Z)\,|Z|} となる。
Y の分布は Z の周辺化によって、
p ( Y ) = ∫ − ∞ ∞ p U ( Y Z ) p V ( Z ) | Z | d Z {\displaystyle p(Y)=\int _{-\infty }^{\infty }p_{U}(YZ)\,p_{V}(Z)\,|Z|\,dZ} と計算される。
この手法で U , V Y , Z 全単射 である。上記の変換は Z が V に直接逆写像され、与えられた V について U / V 単調写像 であるので条件に適合している。これは、和:U + V U − V UV においても同様である。
独立な確率変数の積についても全く同じ手法で計算することができる。
例:2つの標準正規分布の比の確率密度関数 標準正規分布 に従う確率変数 U , V
まず、確率変数はそれぞれ下記の確率密度関数を持つ。
p ( U ) = 1 2 π e − U 2 2 {\displaystyle p(U)={\frac {1}{\sqrt {2\pi }}}e^{-{\frac {U^{2}}{2}}}} p ( V ) = 1 2 π e − V 2 2 {\displaystyle p(V)={\frac {1}{\sqrt {2\pi }}}e^{-{\frac {V^{2}}{2}}}} これを先に述べたように変換する。
Y = U / V {\displaystyle Y=U/V} Z = V {\displaystyle Z=V} これから、
p ( Y ) = ∫ − ∞ ∞ p U ( Y Z ) p V ( Z ) | Z | d Z = ∫ − ∞ ∞ 1 2 π e − 1 2 Y 2 Z 2 1 2 π e − 1 2 Z 2 | Z | d Z = ∫ − ∞ ∞ 1 2 π e − 1 2 ( Y 2 + 1 ) Z 2 | Z | d Z = 2 ∫ 0 ∞ 1 2 π e − 1 2 ( Y 2 + 1 ) Z 2 Z d Z = ∫ 0 ∞ 1 π e − ( Y 2 + 1 ) u d u u = 1 2 Z 2 = − 1 π ( Y 2 + 1 ) e − ( Y 2 + 1 ) u ] u = 0 ∞ = 1 π ( Y 2 + 1 ) {\displaystyle {\begin{aligned}p(Y)&=\int _{-\infty }^{\infty }p_{U}(YZ)\,p_{V}(Z)\,|Z|\,dZ\\&=\int _{-\infty }^{\infty }{\frac {1}{\sqrt {2\pi }}}e^{-{\frac {1}{2}}Y^{2}Z^{2}}{\frac {1}{\sqrt {2\pi }}}e^{-{\frac {1}{2}}Z^{2}}|Z|\,dZ\\&=\int _{-\infty }^{\infty }{\frac {1}{2\pi }}e^{-{\frac {1}{2}}(Y^{2}+1)Z^{2}}|Z|\,dZ\\&=2\int _{0}^{\infty }{\frac {1}{2\pi }}e^{-{\frac {1}{2}}(Y^{2}+1)Z^{2}}Z\,dZ\\&=\int _{0}^{\infty }{\frac {1}{\pi }}e^{-(Y^{2}+1)u}\,du&&u={\tfrac {1}{2}}Z^{2}\\&=\left.-{\frac {1}{\pi (Y^{2}+1)}}e^{-(Y^{2}+1)u}\right]_{u=0}^{\infty }\\&={\frac {1}{\pi (Y^{2}+1)}}\end{aligned}}} が導かれる。これは、標準コーシー分布 である。
関連項目 出典 ^ Probability distribution function PlanetMath ^ Probability Function at Mathworld ^ Ord, J.K. (1972) Families of Frequency Distributions , Griffin. ISBN 0-85264-137-0 (for example, Table 5.1 and Example 5.4) 文献 The first major treatise blending calculus with probability theory, originally in French: Théorie Analytique des Probabilités . The modern measure-theoretic foundation of probability theory; the original German version (Grundbegriffe der Wahrscheinlichkeitsrechnung ) appeared in 1933. Patrick Billingsley(英語版) (1979). Probability and Measure . New York, Toronto, London: John Wiley and Sons. ISBN 0-471-00710-2 David Stirzaker (2003). Elementary Probability . ISBN 0-521-42028-8 Chapters 7 to 9 are about continuous variables. 外部リンク 『確率密度関数の意味と具体例』 - 高校数学の美しい物語 Ushakov, N.G. (2001), “Density of a probability distribution”, in Hazewinkel, Michiel, Encyclopedia of Mathematics , Springer, ISBN 978-1-55608-010-4, https://www.encyclopediaofmath.org/index.php?title=Density_of_a_probability_distribution Weisstein, Eric W. "確率密度関数". mathworld.wolfram.com (英語). 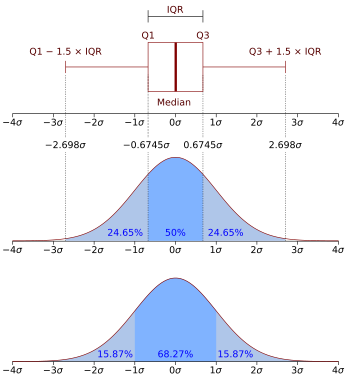








![{\displaystyle \operatorname {E} [X]=\int _{-\infty }^{\infty }x\,f(x)\,dx}](https://wikimedia.org/api/rest_v1/media/math/render/svg/91e3fa656d4fd0a4c5b754f25203e105efd15ef9)




![{\displaystyle f(x;\mu ,\sigma ^{2})={\frac {1}{\sigma {\sqrt {2\pi }}}}\exp {\biggl [}-{\frac {1}{2}}\left({\frac {x-\mu }{\sigma }}\right)^{2}{\biggr ]}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/95e4f8bda207562f7c90ef2f31b9e7dbf0bebdb1)











![{\displaystyle \operatorname {E} [g(X)]=\int _{-\infty }^{\infty }yf_{g(X)}(y)\,dy}](https://wikimedia.org/api/rest_v1/media/math/render/svg/996bc41d8f620112c17234ca8f7b3f2593be87fd)
![{\displaystyle \operatorname {E} [g(X)]=\int _{-\infty }^{\infty }g(x)f_{X}(x)\,dx}](https://wikimedia.org/api/rest_v1/media/math/render/svg/50fb3681bf7d2c3cff167c44eb62534ecf69d617)
















![{\displaystyle {\begin{aligned}p(Y)&=\int _{-\infty }^{\infty }p_{U}(YZ)\,p_{V}(Z)\,|Z|\,dZ\\&=\int _{-\infty }^{\infty }{\frac {1}{\sqrt {2\pi }}}e^{-{\frac {1}{2}}Y^{2}Z^{2}}{\frac {1}{\sqrt {2\pi }}}e^{-{\frac {1}{2}}Z^{2}}|Z|\,dZ\\&=\int _{-\infty }^{\infty }{\frac {1}{2\pi }}e^{-{\frac {1}{2}}(Y^{2}+1)Z^{2}}|Z|\,dZ\\&=2\int _{0}^{\infty }{\frac {1}{2\pi }}e^{-{\frac {1}{2}}(Y^{2}+1)Z^{2}}Z\,dZ\\&=\int _{0}^{\infty }{\frac {1}{\pi }}e^{-(Y^{2}+1)u}\,du&&u={\tfrac {1}{2}}Z^{2}\\&=\left.-{\frac {1}{\pi (Y^{2}+1)}}e^{-(Y^{2}+1)u}\right]_{u=0}^{\infty }\\&={\frac {1}{\pi (Y^{2}+1)}}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/10770de156debb5b0ab958b3cf2018de6577e8a8)







